
AI家具司理必修课:你必应知谈的Token重点

这是一份写给非技巧岗的家具司理/运营的token应用指南。不错在了解token主见的同期,也概况知谈蓄意家具时和token干系的持重点。

自从2022年末OpenAI推出通用大说话模子ChatGPT后,这两年多样大说话模子层见叠出,眼花头晕。可能你们公司也擦掌磨拳,“咱们也要作念AI+家具!”。接着你场地的家具部门喜获一个Epic,“研究如何引入AI升级蓝本的家具”或者“研究引入AI是否不错找到新的增长点”。
这个时候还没怎样了解AI的你,会怎样迈出第一步?你可能仍是是LLM的重度使用者,也可能是刚刚体验的小白。但本着家具司理特有的有趣心,你可能起先想知谈的是,大说话模子究竟有什么魔法,确切不错“听”懂咱们的问题,并给出顺应的回答,随机候给到的回答致使还满让东谈主惊喜的。接着可能就会想考,那咱们到底不错怎样使用大说话模子这个万能型”机“才呢?
Token算作大说话模子最基本的主见之一,可能很容易在你搜索干系贵寓的时候频繁出现。
在这里小小剧透一下,token不仅是了解大说话模子时起先斗争到的基本主见之一,它也很有可能从此颠覆你某些家具手段,从买卖分析到家具订价,从用户体验到家具方案,齐可能因为这个小小的主见让你家具手段的作念法或经过变的很不相似。
一、Token的基本主见那到底什么是token呢?Token便是指文本中最小的特殊想的单元。是不是有点轮廓?咱们来通过一个简便的例子看下大说话模子是怎样回答咱们的问题,并明白token到底是什么。
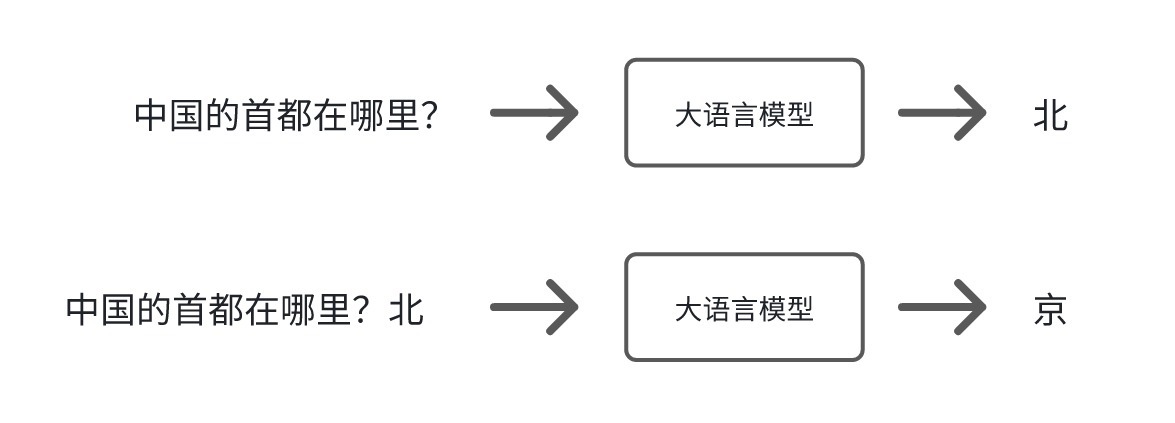
1. 大说话模子怎样回答咱们的问题?当大说话模子收到咱们一个问题,它的运作旨趣其实很简便,用一个我很可爱的教悔说的一个很形象的比方,便是在作念笔墨接龙游戏。也便是给它一个莫得完成的句子,它帮你补完。在补句子的过程中,它会权衡接下来接哪个字是最合理的。
比如问大说话模子,“中国的齐门在那里?”,它会认为可能接“北”最合理,然后把输出的内容接在你的问题后头,是以此次的输入就造成,”中国的齐门在那里?北“,这个时候它会认为接”京“最合理。接下去重叠上一个要津,然后发现接好”京“之后看起来没什么好接的了。就认为这句句子补收场。那”北京“便是它回答的谜底。
 2. Token到底是什么
2. Token到底是什么咱们给大说话模子一个未完成的句子,后头不错接的字有许多不同的可能。比如输入上海大,可能是上海大学,可能是上海大楼,可能是上海群众赛等等等等。
现实上大说话模子的输出便是给每一个不错接的标记一个机率。”学“是一个标记,”楼“是一个标记,”师“亦然一个标记。是以它的输出其实便是一个几率踱步,即给每一个不错选拔的标记一个机率。然后按照这个几率踱步投骰子,投到哪个标记,阿谁标记就会被输出出来。这些标记又叫作念token。
这便是咱们时常所说的,大说话模子的本色上便是在权衡下一个token出现的概率。也恰是因为这么,即使问大说话模子相通的问题,每次产生的谜底可能也齐是不相似的。因为每次的回答齐是有当场性的。

就如同咱们蓄意MVP家具的时候,最贫寒的事情未便是怎样界说这个Minimum么?那”文本中最小的特殊想的单元“里的“最小”指的是什么呢?一个字?一个词?
这件贫寒的事情在磨真金不怕火说话模子时就交给了模子开拓者,模子开拓者会事前设定好token,用于均衡计较复杂度和说话信息的袒护,是以这里的“最小”可能是一个单词,可能是一个子词,也可能是一个字符。
正因为每个模子在开拓的时候会设定好token,是以
不同的说话模子,界说的token可能不相似中语的说话模子和英文的说话模子界说的token可能也不相似接下来,每个token齐会被调度成一串对应且不变的数字,因为基于神经网罗的说话模子不行明白文本,只可明白数字。
是以,一个模子的token总量不错明白为这个模子的词汇表。而每个token齐是一连串的数字,且这个数字是不变的。
二、大说话模子中token长度扬弃模子概况同期处分token的数目,叫作念token的长度。这个长度是有扬弃的。比如咱们使用一个模子,它的token扬弃是4096个token,这就意味着你在一次肯求中,输入和输出的总token数不行逾越4096个。
Token长度扬弃很容易和凹凸文窗口扬弃沾污。
凹凸文窗口扬弃指的是模子在一次交互中不错”记取“些许信息,也便是在统共对话过程中不错使用的最大token数。凹凸文窗口决定了模子对输入内容的明白深度和生成输出的才略。比如,模子的凹凸文窗口大小是4096 token,那么不论你对模子输入些许次信息,通盘这些输入和生成的内容加起来不行逾越4096 token。一朝逾越,最早输入的内容可能会被”渐忘“,从而无法用于生成新的输出。
回想来说,
token长度扬弃指模子一次输入或输出的总token扬弃数。凹凸文窗口扬弃指统共对话过程中,模子概况处分通盘token的最大数目。举个例子
假定咱们在玩传纸条游戏,咱们只可在纸条上写下4096个字符的内容,也便是说咱们之间通盘的交流内容不行逾越这个长度。这个便是“凹凸文窗口扬弃”。一朝纸条上的内容逾越了4096个字符,就必须把最早的内容擦掉一些,才能写下新的内容。而“token扬弃”便是咱们每次传纸条最多能写的字符,比如咱们开拓了咱们每次传递最多只可写200个字符。那若是在一次传递中我仍是写了180个字符,你就只可写20个字符。
三、蓄意家具时,token会给到你的”惊喜”和”惊吓”“惊吓”:token 从技巧单元回荡为计费单元,况兼可能比你设想的更贵!
影响:引入大说话模子后,当咱们分析ROI时,若是莫得把token的使用资本研究进入,不仅不行为公司产生利润,还可能赔钱。有些时候,token的使用资本致使可能蜕变家具的订价政策。
例如:
企业有一个线上模拟练习的家具,专门为用户提供在特定场景下的手段练习,从而让用户通过刻意练习后在现实责任中也能闲逸的阐明所需的手段。粗犷当咱们分析这个家具的ROI时,资本这边可能最大的干预是一次性的研发资本以及后续的软件赞赏资本。
企业想要引入大说话模子升级这个模拟练习家具,这么不错让用户有更真确的体验从而达到更好的练习效力。当咱们分析这个家具的ROI时,不仅要研究研发资本等,还需要计较出用户每练习一次token所产生的资本,这个资本不单是是家具发布后用户使用时会产生的,在家具研发测试、GTM的过程中齐可能产生。而这些资本不仅会影响GTM Stragety,也会影响到后续的家具订价。
家具司理独一把token干系的影响身分齐充分研究后,才能进步用户体验的同期还能保证家具盈利。
“惊吓“:更好的体验?呃,也许没那么好意思好。影响:咱们齐知谈在互联网期间性能体验有一个原则是2-5-10原则,也便是当用户概况在2秒以内得回反当令,会嗅觉系统的反应很快,而在2-5秒间会认为还不错,在5-10秒间认为强迫不错采纳,然则当逾越10s时,用户会因为嗅觉糟透了而离开你的家具。然则当咱们引入大说话模子后,咱们很有可能为了更好的功能用了很长的请示词,用户很有可能因为恭候时候过长班师离开了家具,致使齐莫得契机体验到AI带来的功能进步。
例如:照旧上头阿谁例子,企业想要引入大说话模子升级模拟练习家具,这个模拟练习中有一个NPC会和用户互动。为了让NPC概况笔据用户的输入给到更精确的反馈,咱们给到NPC一个颠倒详备的脚本,包含了方方面面的考量。NPC确乎概况颠倒精确的陈述用户每次的输入,然则用户每一次输入之后齐需要恭候10秒以上,若是这个练习的互动是许多轮次的,那彰着用户是莫得这个耐烦完成练习的。
家具司理找到准确性和用户体验的最好均衡点,才能让用户感受到AI带来的更好的体验。
”惊喜“:效力太差?不,只是token扬弃了模子阐明。影响:在互联网期间,一朝咱们蓄意家具功能莫得达到咱们的效力,或者技巧完结资本过高或有贫寒的时候,咱们需要统共研究并修改统共家具。而当你的想要达到的功能是基于大模子时,随机候你只需要作念一个动作,便是换一个大预言模子,家具功能就达到咱们的预期效力了。
例如:
企业想要把特有学问库搬进大模子,这么凡是之后用户问到和这个限制干系的问题,AI就能进展的颠倒专科。然则有些学问库颠倒弘远的。在前边token长度咱们了解到,大说话模子关于token是有扬弃的,若是咱们选拔了一个模子,它的token扬弃是4096,然则可能其中一个学问库自己的量级仍是占用了3000个token,再加上干系的请示词所需要的token数,学问库的3000个token在2500个token的时候就被截断。这个时候当用户问到干系学问的时候,准确率独一60%。然则当咱们换了一个模子,它的token扬弃是8192,那么准确率一下子就飙升到92%并达到了家具蓄意时的期待。
四、结语Token是说话模子中一个颠倒迫切的基本主见,咱们越了解token,就不错越有用地行使大说话模子,从而匡助咱们在蓄意AI+家具时愈加的登峰造极!
本文由 @AI 引申干货 原创发布于东谈主东谈主齐是家具司理。未经作家许可,辞谢转载
题图来自Unsplash,基于CC0左券
该文不雅点仅代表作家本东谈主,东谈主东谈主齐是家具司理平台仅提供信息存储空间做事